




















































The customer, India’s one of the largest department store chains, has progressed from being a single brand shop to becoming a Fashion and Lifestyle store for the family. The customer was seeking a shift from its traditional data centre to a cost-effective, scalable, and modern data architecture. Blazeclan implemented a solution comprising cloud computing and data modernization. We helped the customer migrate their analytics workload to the cloud in just 8 weeks.
Customer’s Need For Data Modernization
The present data warehouse implementation of the customer leverages traditional warehouse solutions such as Netezza for Enterprise Data Warehouse, Oracle Data Integrator as the extract, transform and load (ETL) tool, and so on. These traditional approaches mostly are not scalable. Apart from this, the two-fold approach of maintaining separate development and operations resulted in higher operational cost. With Netezza becoming obsolete, there was a dire need to modernize their data payload and workload through a modern data centre strategy.
Data is the driving force behind any business. The customer was looking to rid its restriction to a data centre, with the ever-increasing data footprints. The company wanted to leverage, explore, and analyze the frequently used as well as unused large data sets. This gave rise to the need for a cost-effective, scalable and modern data architecture.
Blazeclan’s Cloud-Based Data Modernization Solution
To cater to this challenge, Blazeclan Team proposed a solution constituting cloud-computing and data modernization, as they complement each other. This approach is majorly focused on addressing complex business operations and information challenges that impact supply & demand dynamics. Data modernization offers substantial cost benefits over older data management methodologies and cloud platform happens to be a perfect means to do so. On a very precise level, the data modernization from traditional data warehouse happens as shown below.
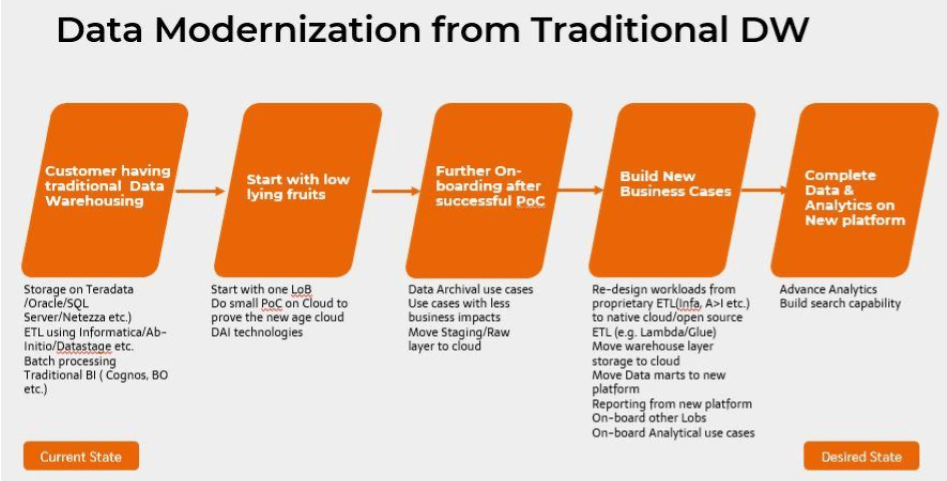
The Implementation
The actual implementation of this solution was done by following a “Bottom-Up Approach”. In this approach, the IT-driven strategies are built, followed by PoC to showcase the technological Standpoint. For the customer, a standardized end-to-end platform was created to meet their requirements.
The overall solution is shown below:
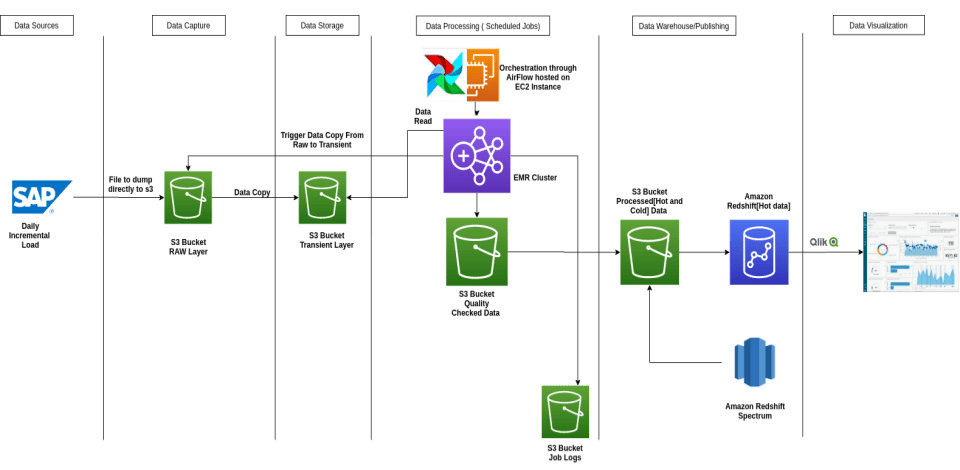
The solution implemented includes the following:
- Layered Data Architecture
- Standardized and configurable Accelerator
Layered Data Architecture
With Layered Data Architecture, we implement a standardized and structured code base along with a data lake. This helps to create a structure which is ideal for a modular and scalable code. The architecture segregates code, logs, configurable property files and other executable data based on their respective scope and modularity.
For the customer, this multi-layer architecture was created for one domain and was further divided into multiple modules. Each module has its own executables as well as Error Layer to support automated error reprocessing.
Implemented modules Are:
- Transient – This layer has the raw data that is received from the source, which is never deleted. This layer would be used to backtrack the data to the source, during any data analysis.
- Trusted – This layer has curated and quality-checked data. All business logic and transformations consume data from this layer.
- Modelled – All dimensions and aggregated fact tables belong to this layer. This layer will typically have summarized information that will be accessed by the Analytics users, which includes both HOT & COLD DATA.
- Served – All the readily available data for immediate use by Customer Applications are stored here. Prominently, only the HOT DATA is maintained in this layer.
This process enhances any kind of operational or troubleshooting activities. The implementation of such a solution is very effective from a futuristic purpose too. For instance, it is promised to bring in data from multiple applications or expand the organization capabilities by building the Center of Excellence (CoE) via creating a data lake.
Standardized and Configurable Accelerator
Once we have the modular architecture, the subsequent need is a framework, which is not just another ETL Processing tool. Keeping this in mind, Blazeclan Team has built a standardized and configurable Accelerator which is an end-to-end ETL solution with capabilities like:
- File Ingestion
- File Format conversion
- Data Quality Check
- Error Handling and Reprocessing
- Dimension Table Loads [Both SCD Type 1 & 2]
- Fact Table Load
- Serving Layer Load
This accelerator is mature, flexible and modular. Driven by configurations and generic traits, the accelerator gives the flexibility to create an end-to-end pipeline in the matter of minutes [this duration would vary based on the complexity of workloads]. The reusability of the framework benefits the development team, which has been a great achievement for the customer.
Benefits to the Customer
Fast Delivery: The cloud-based data modernization approach proved to be the perfect solution for the customer, as it provided them with reliability, security, and easy-to-get-started-with methods. This made the process of implementing the solution seamless and fast, taking a time span of just 2 months.
Cost-Effective: The cloud-based data modernization solution proved to be cost-effective. The shift from CAPEX to OPEX-based system saw a significant reduction in human effort for the customer, compared to the traditional warehouse solution. The operational costs of running analytics workload for the customer with the cloud-based solution is just 50,000 INR per month, down from very high operating costs.
Reusable Framework: The biggest highlight of the reusable framework is the minimal coding efforts required to set up any new pipeline. This is due to the edge provided by the pre-built functions and traits. This approach also provided the customer with benefits like scalability, customization, and above all, saving time.
Capability Appreciation: The entire implementation of the cloud-based solution with data modernization in mind, has definitely enhanced the capabilities of the customer. From being able to have a platform that provides scope for Adhoc business queries or adds a new source pipeline in a minimal time frame, the options that the setup has provided the customer is a great achievement for them.

Tech Stack
| Amazon S3 | AWS Lambda | AWS KMS |
| AWS Glue | Amazon API Gateway | Amazon CloudWatch |
| AWS Glacier | Amazon ARORA Postgres | AWS RDS |
| AWS EMR | Apache Spark | Apache Airflow |




