




















































The customer is an alliance of premier telecom operators. It crafts innovative solutions for its members and helps them secure revenue streams ceaselessly through new opportunities. With an extensive customer base, the customer has its presence across more than 30 countries across APAC and MEA.
The Challenge
The leading mobile alliance wanted to improve the efficiency of its invoicing system. Their system faced inconsistencies related to time and efforts due to manual intervention in the classification of bills and usage of their members.
The existing invoicing system of the customer has various data sources in different formats, namely, XLSX, XML, CSV, and TXT. Part of the billing workflow was to map the bills and usage of their members into the right spend category. This workflow involved manual intervention when uploading new bills and usage details. The key pain area of the customer was the rule-based categorization of usage and spend associated with multiple operators. Due to this, the entire invoicing system faced inefficiency.
The Solution
The customer partnered with Blazeclan for helping them out in improving the efficiency of their system, saving their time, and reducing manual intervention to the minimal. Blazeclan’s expertise reflected clearly in its understanding of the customer’s requirements and how well-placed we were in delivering the most appropriate solution.
The system ran on the rule-based engine. When a new unique record was introduced, the workflow could not infer a new pattern and depended on the programmer and business analyst for updating the record. Blazeclan identified that implementing an approached based on Machine Learning was most suitable for learning new data patterns over time and deducing the classification correctly.
The Approach
- Using ML/AI, the process of mapping the spend and usage categories was automated with an acceptable error margin.
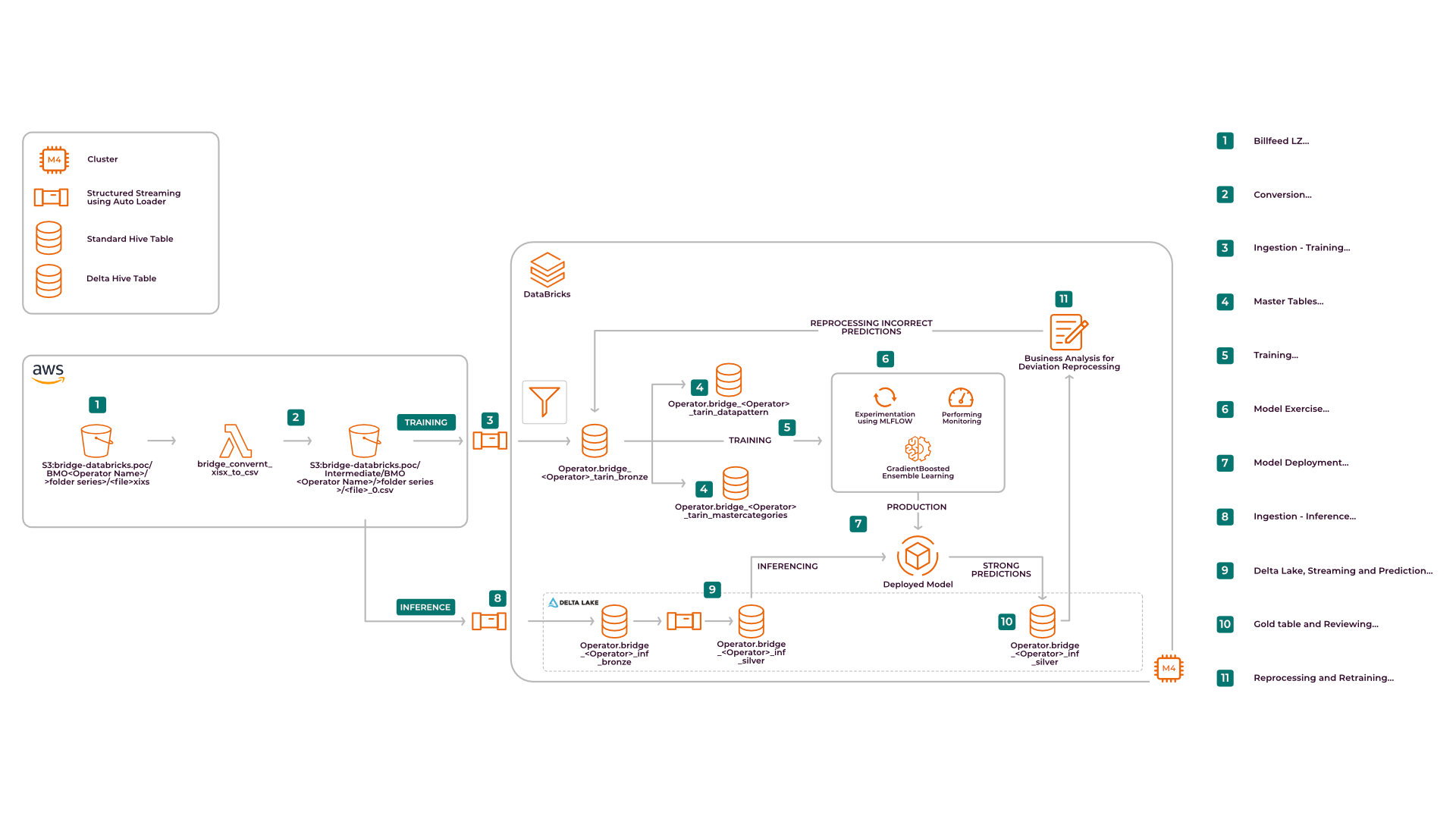
- The data from multiple operators was captured using Databricks – Delta Lake. A set of operations were performed on this data, such as initial processing, data clean-up, and feature engineering.
- Databricks Auto Loader was used for structured streaming and capturing data in near-real-time.
- An ML flow has been established for tracking the ML metrics and deployment of latest system version through continuous training.
The solution deployed has paved the way for decommissioning of the rule-based engine and long-term ML automation of the system.
Architecture Diagram
Benefits Achieved by the Customer
- The need for manual intervention, whenever record categorization failures occur, has been eliminated via automation using ML/AI.
- The solution delivered the customer with Confidence Score, which helps them in identifying false positives associated with records.
- Use of Databricks Delta Lake meets the purpose of enriched data, which is being stored at a single repository for leveraging advanced analytics and insights.

Tech Stack
| Amazon S3 | AWS Lambda | Amazon VPC |
| Amazon CloudWatch | Delta Lake | MLflow |
| HiveSQL | PySpark | Auto Loader |




