



















































We’ve heard this story before!
We’re all thoroughly familiar with the serverless compute service of AWS — the AWS Lambda! We’ve been using it heavily for various kinds of tasks — from event-based invocations to stream processing to scheduled runs — we’ve seen it all!
One of the challenges, however, has been the dependency management. For example — suppose we have a Lambda function that parses a JSON, and then uses that data to update the DB — say a MySQL RDS instance. For a Java-based Lambda, apart from the core libs — what we’d need to bundle with the Lambda function archive (jar or zip), are the JSON parsing jars as well as the Database connection (say, MySQL connector) jars. For a Python-based Lambda, the corresponding libs would need to be added, and likewise, for other run-times.
Cold starts
Now imagine that we have several such Lambda functions (Handlers), all performing various kinds of operations, and hence referring to all kinds of libraries or jars.
So the ‘uber’ jar for our Lambda would consist of all the dependencies which the functions (handlers) would need upon their individual/simultaneous invocations. Such Lambda functions suffer from what is known as a “cold start” especially in compiler-based run-times — wherein the function bootstrapping takes some time.
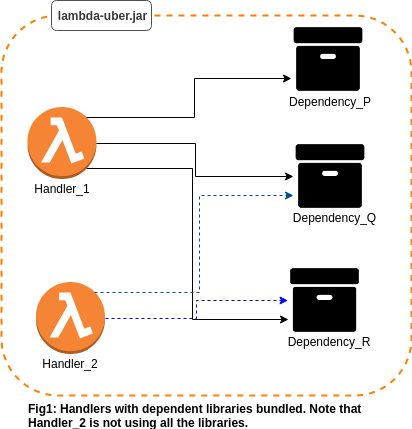
What this also results in, is a big blob of an archive (see Fig.1), whose deployment is both time and resource consuming. Furthermore, over time, dependency management becomes an involved task! The issue is compounded by the fact that there could be multiple versions of the libs — say new ones according to the runtime versions or with security fixes. Now, modifying these dependencies in the original Lambda “bundles” could be a breaking operation — as we may not always be able to predict the run-time behaviour.
Layers to the rescue!
A new feature of AWS Lambda services, Lambda layers comes-in handy to address the issue of dependency management — and hence helping in smarter bundling of jars and quicker deployments. The dependency version management is another byproduct of layers, as we shall see later in this post.
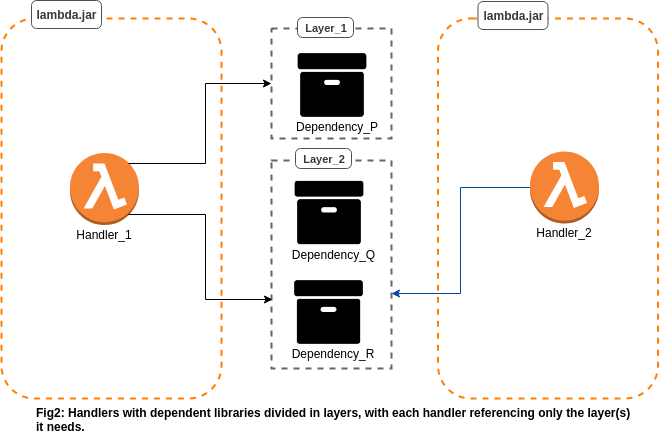
Refer to Fig.2, which depicts how the previous dependency scenario (Fig.1), can be broken down in Layers, with each of the handler referencing just the layer(s) having relevant dependencies. The Lambda .jar (or archive), thus created is a lightweight one, with only the handler code.
Everybody loves SAM!
Let’s further concretize our understanding with the help of a simple example. We’ll be using SAM templates to define, and subsequently deploy, the stack for this project.
Consider a Maven-based Java Hello World Lambda project (hello-world-project), which returns a JSON string with some random data. For generating the JSON string, we’d be using Google’s JSON-simple library. In a conventional (non-layered) approach, the classes from this jar would end-up getting bundled within the Lambda uber jar, as an outcome of the mvn package command.
The corresponding SAM-template defines an AWS API Gateway-based resource URL, and the Lambda function that caters it, with a very simple format:
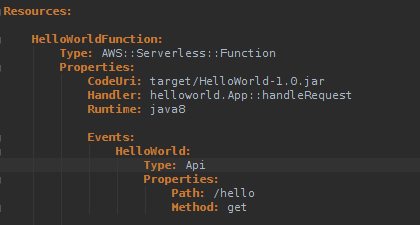
Note that the HelloWorld-1.0.jar shown above, would be having the handler classes, along with all the dependencies.
Breaking free!
Now, let’s take an alternate approach, and separate out these (and related) dependencies in a layer of their own! Although one doesn’t have to, but one can utilise SAM-template based deployment for this as well. This would help us in tracking (CloudWatch logs) as well as maintenance of the layer in future.
For Java, a Lambda layer expects the following folder structure:
java
└── lib
├── dependency1.jar
└── dependency2.jar
└── …
In a new Maven-based Java project (library-layer-project), we define all the dependencies we want bundled in the target layer. For our simple example, we’d define, the dependency for JSON-simple in the pom.xml.
Moreover, the corresponding SAM-template defines this layer like so:
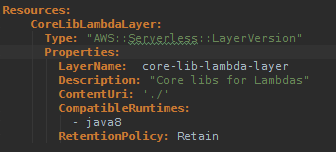
Upon successful deployment, this Lambda layer is available to be referenced in any Lambda function, via its ARN.
So, the next step for us would be to modify the original project’s SAM template, to provide the ARN of the Lambda layer we would want it to access. The resulting SAM-template definition, thus, looks like:
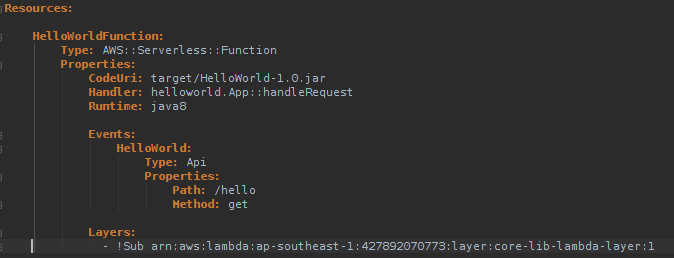
Notice the ‘Layers:’ parameter added, which now references the core-lib-lambda-layer that we deployed. As of this day, AWS Lambda service supports up to five layers being referenced from within a given function (handler). So imagine scenarios where a bunch of your Lambda functions perform only DB operations — they can reference only Database lib layer, and similarly, the Lambda functions that help in authentication refer to only the layer with those jars.
Layers in other (non-Java) runtimes
Note that we followed a particular directory pattern for the Java-based dependency layer under discussion. Analogous to this, there are specific directory patterns to be followed while creating layers for other runtimes.
For instance: a solution that has multiple Node.js-based Lambda functions, can make use of layers to share the libraries amongst them. A layer structure, thus, would be something like:
parser-layer.zip
└── nodejs/node_modules/parse-json
└── nodejs/node_modules/xml2js
Layer versions
Another feature of Lambda layers is the automatic versioning. Notice the ‘:1’ in the ARN for Layer in the above image. Any subsequent deployment of the same layer automatically bumps-up this number.
Utility of Layer versioning
Versioning is very useful in cases where you would want to update or test your Lambda functions with new library versions — be it third-party or your own! So, continuing with our example — suppose Simple JSON comes-up with a new version, which has security patches, but not all features are backward compatible. Another way to look at it is: suppose there’s a new library that works only with the latest run-time of the platform you’re working on.
In such cases, you can deploy a Lambda function, and make it refer to the newer (latest) dependencies, by using the corresponding ARN suffix (:4 in the sample ARN below):
arn:aws:lambda:ap-southeast-1:427892070773:layer:core-lib-lambda-layer:4
Internally, the Lambda ecosystem kind of ‘flattens’ your dependencies along with the function definition. Thus, any future invocations of a given Lambda function are always tied-to the version of the layer it was bound to.
Sounds like fun? It is! Go ahead and start using the Lambda layers to manage your dependencies better, and considerably reduce your Lambda function footprint.


