




















































The customer is a global leading energy and solutions provider, exploring both renewable and hydrocarbon energy, ensuring excellence through their integrated business model. The energy giant was looking for a way to optimize its enterprise-wide access to data and bridge data gaps with a data lake and warehouse solution.
The Challenge
The customer wanted to establish an enterprise data hub (EDH) to meet and govern their data needs. They aimed at becoming a data-driven organization with this pilot project, which was a part of their initiative to create a Minimal Viable Product (MVP) on a pivot. The customer wants to aggregate and store data sets from multiple sources and consolidate them into a single infrastructure. Key challenges involved
- Restrictions in the deployment environment.
- Providing data in the desired format at the desired frequency.
- Requirements to change internal data collection/entry process.
- Lack of pooled resources.
The Solution
Blazeclan advised the customer to leverage the AWS cloud services to achieve a secure, scalable and high-performing data architecture. This will offer them with efficient consolidation and governance of data, enterprise-wide visibility & access, and automated reporting.
The solution will enhance the frequency of updates, thereby allowing the customer to focus on data analysis and implement preventative measures. The whole MVP solution involved use of a hybrid cloud environment. The data from SAP was processed and onboarded using Azure and the rest of the data sources were onboarded using AWS cloud.
The Solution Approach Followed
- Leveraging the approach of ETL using Talend to process data through AWS architecture and serve data to Pivot.
- Develop ETL using data sources of the incident management system (IMS), electronic Permit to Work (ePTW), and plant information (PI), which will be consumed by the Pivot.
- The data has been collected and processed in the AWS infrastructure using various tools and services.
- Visualization logics and KPIs have been used to improve operational excellence by leveraging the PI.
The implemented solution triggers a series of automated processing pipelines to process data according to the model and push it into the data warehouse. The data is consumed in a form of report which highlights analytics and statistics for making informed decisions.
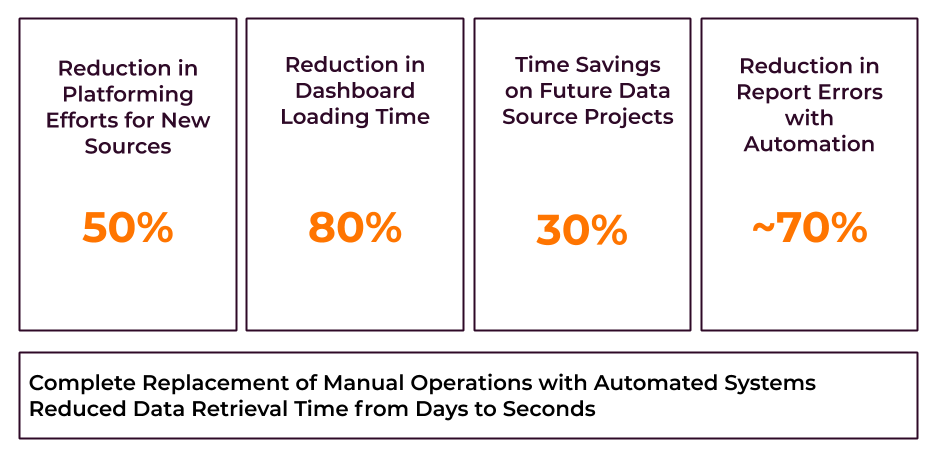
Benefits Achieved by the Customer
High Scalability: The data lake solution provided the customer with the ability to scale their infrastructure according to the changing business demands. The solution further enabled a new auto-scaling feature with minimum or zero downtime.
Automation: Automated data collection, storage and management enabled the customer’s application teams to scale their deployment speed. Automation and data ingestion enables the customer to have a consistently updated view of business performance and customer behaviour.
Analytics-Driven Business decisions: Consolidation of all data sources in a single platform facilitated the customer in data accessibility and analysis. They were able to glean incisive insights from the analysis of data that enabled informed decision making.
Tech Stack
| Talend | Amazon EC2 | Amazon S3 |
| Amazon Redshift | Amazon API Gateway | AWS IAM |
| AWS KMS | Amazon RDS | Amazon VPC |
| AWS Certificate Manager | AWS Firewall Manager | Amazon Cloudwatch |
| AWS Aurora Serverless | AWS Lambda |




