























































The Challenge
The AWS Cloud operates in 43 Availability Zones within 16 geographic Regions around the world, with announced plans for 11 more Availability Zones and four more Regions. Offering a broad set of more than 70 on-cloud services, AWS certainly helps organizations to be agile and reduce their time to market by implementing numerous services in an IT infrastructure.
But is the transition of migrating the databases from one AWS Service to another equally laid-back and corresponding to optimizing the IT infrastructure particularly in Data Warehousing and Data Analytics applications?
Taking a definitive illustration, any Data Warehousing/Data Analytics application contains at least one of the three AWS services mentioned:
- Amazon S3
- Amazon RDS
- Amazon Redshift
- Amazon EMR
- Amazon DynamoDB
Moving data between these services becomes too much of a hassle.
For a hassle free migration, ETL can also be implemented as a solution to provide support to AWS services. Nonetheless, there is an orchestration required to run jobs and write scripts for sending notifications. Furthermore, as we use AWS services, the scripts containing CLI command to spin up and spin down EC2 Instances/EMR clusters is required for cost reduction.
With such complex implementations and unmanageable systems, what if there is an option available to have a data workflow with integrated orchestration along with notification services providing simple ways to spin up and spin down AWS resources.
AWS Data Pipeline
AWS Data Pipeline is a web service that helps the movement of data between different platforms at specified intervals. It primarily consists of three parts:
- Pipeline – Flow describing the movement of data
- Scheduler – For scheduling the data flow
- Task Runner – Task Agent application that polls AWS Data Pipeline for scheduled tasks and executing them on computational resources
AWS Data Pipeline acts as a source to create a workflow with components corresponding to other AWS services used in a Data Warehouse/Data Analytics application. AWS service components like S3, Redshift, RDS, EMR, EC2, and SNS can also be integrated into it.
Working on AWS Data Pipeline
AWS Data Pipeline includes creating a workflow in three different ways i.e.:
- AWS Console
- AWS CLI (Command Line Interface)
- AWS SDK with Language specific interface
For instance, the input file received on S3 is first processed through a Pig script on EMR in any classic Data Warehouse Application on AWS. After processing the output file, it is then loaded on Redshift which acts as a source of reporting to any other downstream system or analysis. The user can also schedule it and send appropriate notifications.
The workflow for the implementation of the above scenario in Amazon Data pipeline appears as mentioned below:
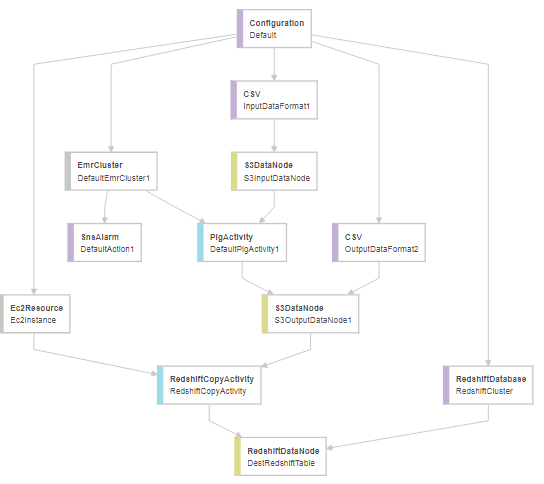
The components of the afore mentioned workflow include:
- Configuration: Contains metadata at a workflow level, for e.g.:
- Name of the workflow
- Scheduling
- Storage location for logs
- Input Data Format: Contains metadata for the file format provided as input, for e.g.:
- Number and names of columns
- Format of the file such as CSV
- EMR Cluster: Configuration for EMR cluster is defined in this component. The Pig script runs on this cluster. The details included are:
- Number of nodes
- Type of node
- Type of pricing to be used for EC2 cluster
- S3 Input Data Node: Contains metadata for the Input file, for e.g.:
- File path
- Manifest file path
- Encryption, etc.
- SNS Alarm: This component is used for integrated SNS service for setting up the alarm when the PIG activity is successfully completed.
- Output Data Format: Similar to Input Data Format, this specifies the metadata for the file format for output file after being processed by the Pig script.
- Pig Activity: Contains the S3 Path of the pig script along with other metadata information like:
- Name of the cluster on which the job will be run
- Arguments for the PIG script
- Maximum retries
- S3 Data Node: Stores the path of the output file processed by the PIG script on the EMR cluster.
- EC2 Resource: Contains the data for the EC2 server launched to trigger the copy command on the Redshift cluster. It contains data for:
- Type of EC2 instance
- Type of pricing used for the instance
- Redshift Database: Contains information on the connection to the Redshift cluster. For e.g.:
- Connection URL
- Username
- Password
- Redshift Copy Activity: Contains information such as:
- The EC2 instance which will trigger this
- The Number of retries
- Copy command options
- Redshift Data Node: Contains metadata like:
- Destination table name
- Schema for Destination table
The workflow determines the order of the load, further terminating the orchestration of any other framework. Integrated SNS takes care of the notifications, and data load operations are easily configured by the Data Pipeline components.
Moreover, this workflow provides an option to spin-up and spin-down the EC2 instances and EMR clusters whenever required to reduce the cost. Another option available is the “Warm” EC2 instances that can be installed using the Task runner JAR on these EC2 Instances. The Task runner process continuously polls the Data Pipeline for any instructions it may have. Incase of EMR cluster, the process will run on the name-node.
An important guideline to the user here, do not hardcode the input and output paths for any activities in Data Pipeline as they are determined by the workflow. For an instance, the pig script without hard coding appears similar to this:
part = LOAD ${input1} USING PigStorage(‘,’) AS (p_partkey,p_name,p_mfgr,p_category,p_brand1,p_color,p_type,p_size,p_container);
grpd = GROUP part BY p_color;
${output1} = FOREACH grpd GENERATE group, COUNT(part);
Here, the usage of “$” for ${input} and ${output} is applied instead of hardcoded S3 paths. The same code can also be applied for the task runner JAR on a non-AWS machine to integrate it with AWS pipeline.
Applying business logic on AWS Data Pipeline
The components provided by AWS Pipeline are restricted yet authoritative. For instance, a business logic can be implemented in the form of PIG/HIVE/MapReduce script to be integrated with the AWS Data Pipeline. One can implement the logic in the form of SQL query and integrate it in the form of an “SQLActivity” and a “ShellActivity” to run on an EC2 instance.
Another use case for this can be while looping multiple files and processing them. We can use various components of AWS Data Pipeline to implement this business logic in an “inner” pipeline. The “outer” pipeline can have a below workflow:
The Shell Activity can have the script which will loop through the input and output S3 paths and execute the CLI command to execute the inner Data Pipeline with these paths as parameters.
In a nutshell, working with AWS Data Pipeline is slightly altered from working on regular ETL tools, but it certainly utilizes the benefits of cloud better.


