























































What is SRE?
Site Reliability Engineering (SRE) is a method to apply the aspects of software engineering to IT operations to make the systems scalable and reliable by bridging the gap between the development and the operations team. The two core components of the SRE model include Automation and Standardization.
This traditional approach started to change at Google in 2003. Benjamin Treynor Sloss brought the concept of SRE into the picture for the first time by finding a site reliability team. In his words, he described it as: “It’s what happens when you ask a Software Engineer to design an operations function.”
Site Reliability Engineer purpose is to keep the organization focused on what is extremely important for their customers, making sure that the platforms and services they rely on are accessible when they need them. Some companies that have adopted the SRE approach to their organizational structure include LinkedIn, Dropbox, Airbnb, IBM, Netflix.
SRE teams are in charge of code deployment, configuration, and monitoring, along with availability, latency, change management, emergency response, and capacity management of services they provide.
Challenges solved by SRE model :
Site Reliability Engineers focuses on handling changes faster and correspondingly deals with the risks associated with those changes. Following are some of the challenges that the SRE model tends to solve :
1. Toil Avoidance
The main question that pops up here is, What is Toil?
Toil is the kind of work that comes with running a production service and is usually manual, repetitive, automatable, tactical, has no long-term value, and scales linearly as the service expands.
The Toil should be minimized because it :
- Slows down Progress
- Career Stagnation
- Low Morale
A toil is dealt with in the following three steps :
- Identification of Toil
- Measuring Toil
- Eliminating Toil
2. Eliminating Bad monitoring
Ensuring better monitoring can ease your problems and help you to resolve issues at a faster pace. Lousy tracking is time-consuming, and here are a few examples of how it might go wrong:
- Alerts that aren’t useful (i.e., spam)
- A large number of pagers or tickets
- Customers keep asking for the same item.
- Dashboards that are impenetrable and crowded
Now, you investigate the sources of Toil associated with inadequate monitoring by:
- Keeping all of your tickets in one place
- Keeping track of the status of tickets
- Identifying familiar notification/request sources
- ensuring that the operational load does not exceed 50%
3. Creating a healthy incident management system
The importance of a well-functioning incident management system is critical in ensuring that your service is well-managed in the event of an outage. Some of the measures to look forward to including:
- Put incident management principles into practice: Incident management guides you on setting up a structure with predefined roles and tasks to help you prepare your response for an emergency.
- Try building human connections: You can do so by creating your customized list of people of all domains, including tech leads, managers, developers, for your urgent task-related situations. Also, you can prepare a document containing subject matter experts you can reach out to when required.
- Creating Communication Channels: While investigating and dealing with an outage, one of the most critical steps includes bringing the entire team on the same platform level in terms of communication.
- Make no-fault(blameless) postmortems: After the issue is solved, an autopsy is required. The primary goals are to ensure that the problem is documented, with all its causing factors being noted and the measures that can help the case not occur in the future.
What is DevOps?
DevOps(Development and Operations) focuses on establishing a combination of cultural practices, tools, and a set of methodologies that aid organizations in delivering their services at a faster rate. Both SRE and DevOps work towards a common goal of bridging the gap that for long existed between developers and the operations team.
Patrick Debois coined this term in 2009 as the combination of the development and operations of the word, which signified its primary goal of combining development and the operations team.
But the question here is. Why in the first was DevOps required?
According to the changing requirements of the business users, with frequent requests of adding new features and services, there was a requirement of deploying these changes faster yet allowing the production system to stay away from any outages caused by the changes in the system.
And that’s where DevOps comes into the picture by integrating the development and the operational team into a single, structured workflow to cater to the user’s needs with faster deployment yet in a stable and integrated environment.
What problems does the DevOps team solve?
1. DevOps Delivers More Value to Customers
Every organization’s backbone provides value to its customers, and effective DevOps solutions increase value by eliminating or automating repetitive or low-value operations. Which ultimately lets the IT staff focus on more significant issues, resolving them, and—in turn—making them routine and eligible for automation. Furthermore, iterative DevOps processes enhance innovation, management, and flexibility that take the technology to new heights without concentrating on everyday tasks. Hence, it ultimately delivers both real and perceived value to your customers.
2. Minimize Production Cost
With legitimate joint effort, DevOps teams help chop down the administration and creation expenses of your specializations, as both support and new updates are brought under a more extensive single roof.
3. Provides a Highly Transparent Working Environment
With the advancement of coordinated effort, this cycle considers simple correspondence among the colleagues, making them more engaged in their specific field. Along these lines, joining DevOps strategies has additionally prompted an upsurge in usefulness and productivity among the representatives of an organization.
4. Reducing Cycle Time
When you make a solid DevOps measure, you are empowering nimbleness inside your turn of events and activities groups. Groups can make changes to the stage and carry out new elements quickly. Since DevOps groups are continually going through testing and organization, they can fix bugs and issues as they emerge and react to client needs rapidly. Process duration can be radically diminished in light of the fact that the cycle is incorporated into the interaction.
5. Enhances Market Time
DevOps accelerates the time to market as it allows teams to move faster. Furthermore, DevOps allows teams to quickly respond to customer requests because it provides team feedback on features in real-time. The key to DevOps speeding up the time to market is that it reduces the complexity of the development process by using automation which saves time for repetitive operations. All the functions under the DevOps strategy go hand in hand, which saves time and ultimately leads to the speedy delivery of products in the market.
5 Key Pillars of DevOps
These Five Pillars are CALMS:
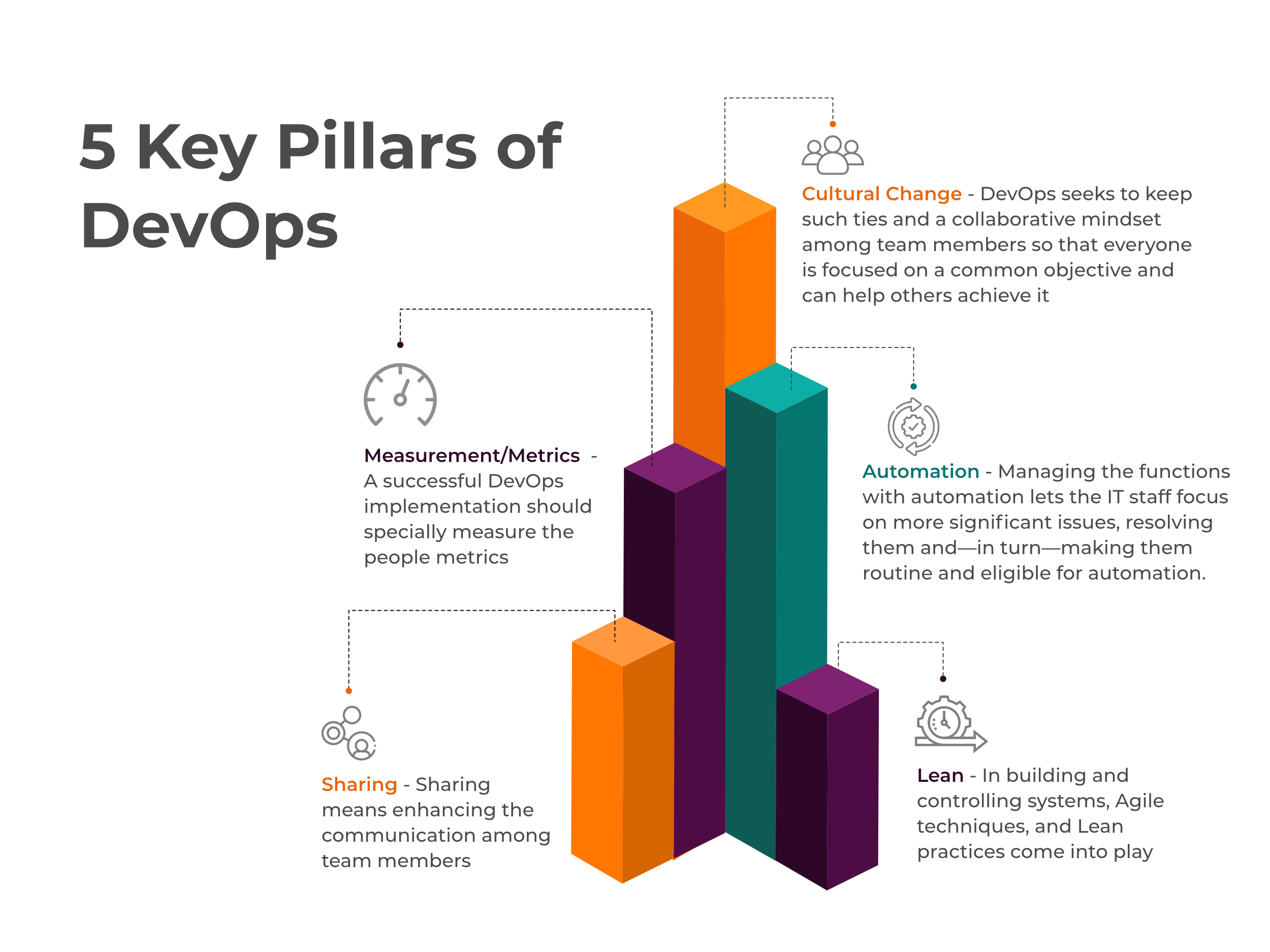
Cultural Change – Teamwork is something that makes a task fulfilled effectively. A collaborative team is essential for the delivery of reliable software and business benefits.
This is something that cultural change means. DevOps seeks to keep such ties and a collaborative mindset among team members so that everyone is focused on a common objective and can help others achieve it, whether it’s within your area of expertise or not.
So the first step is to start with people having a proper mindset that concerns all team members. So basically, in DevOps, engineers are encouraged to do something out of their comfort zone, aiming to make them full-stack engineers.
Automation – As the world is turning to a Digital path, we always find a solution to complete our tasks digitally. So Any industry that encounters repetitive tasks can use automation. That helps to reduce direct human involvement and to make the job more productive.
Managing the functions with automation lets the IT staff focus on more significant issues, resolving them and—in turn—making them routine and eligible for automation. Tools for release management, provisioning, configuration management, systems integration, monitoring and control, and orchestration are essential aspects of building a DevOps system.
Lean – In building and controlling systems, Agile techniques, and Lean practices come into play. Poor testing cycles allow frequent and effective checking out that is core for performance. Automating the whole thing can be a pitfall that overcomplicates the infrastructure.
Consequently, engineers have the consciousness of maintaining everything minimal yet beneficial. However, that doesn’t best challenge automation. Code deployments to the manufacturing environment need to be small and shared, and whole packages must be advanced in an easy way to recognize. It additionally applies to team size; large groups find it extra challenging to agree on something.
Measurement/ metrics- it is the next important aspect of DevOps and placed in the feedback process. A successful DevOps implementation should specially measure the people metrics. Frequent releases give significant advancement but, at the same time, can affect the production environment.
This is why an evolved utility needs to be prepared with valuable metrics and monitored in actual time. In case of problems, it should not be like who has created that bug or issue. Instead, the team should work together on solving that issue. This will further fulfill DevOps’s blameless culture necessity. Teams can also monitor how new features influence user behavior.
Sharing – Sharing means enhancing the communication among team members. They can share their ideas, discuss the problems and challenges they face, and even their success stories, which are essential for the team to work as a team.
This way, Sharing ideas always comes up with the gates of feedback and so leads to improvement. Therefore, it’s essential to share ideas, experiences, and thoughts within the team and even outside the company. Discussion of what problems they are facing, new architecture introduction increases interaction and involvement for getting ahead with suggestions, improvement which also adds motivation. And this also helps all the team members to have a track of what their project is heading to.
SRE Vs. DevOps Responsibilities
1. Monitoring and Remediation:
DevOps often deals with the situation before a failure occurs. Furthermore, it assures that conditions do not result in system downtime.
At the same time, SRE teams deal with the aftermath of a failure. As a result, a postmortem for root cause analysis is required. Furthermore, the primary goal is to maximize uptime and eliminate failures for long-term dependability.
2. SDLC (Software Development Life Cycle) Role:
The primary focus of DevOps during a software development is on the efficient creation and delivery of software products. It must also guarantee Zero Downtime Deployment (ZDD). It also necessitates the identification of blind spots in infrastructure and applications.
Site Reliability Engineer, on the other hand, efficiently controls IT operations once the application is deployed. Therefore, it must also be able to withstand high application uptime and stability in a production setting.
3. Cost and Speed of Incremental Change:
DevOps is all about releasing new updates/features faster, deploying them more quickly, and maintaining continuous integration and development. Furthermore, the expense of accomplishing all of this is insignificant.
SRE, on the other hand, focuses on instilling resilience and robustness in new updates/features. It does, however, anticipate slight modifications at regular periods. This allows for more space to track changes and take corrective action in the event of a failure. Furthermore, the bottom line is effective testing and remediation to lower the cost of failure.
4. Prime Measurements:
CI/CD is at the heart of the DevOps measurement strategy. As a result, it prefers to track process improvements and workflow productivity to keep a good feedback loop going.
SRE, on the other hand, supervises IT operations through the use of specified criteria such as Service Level Indicators (SLIs) and Service Level Objectives (SLOs) (SLOs).
DevOps became a common practice among organizations in the past decade. However, recent years have witnessed organizations embark on the way to becoming product-led and sustainably improve reliability. SRE helps organizations achieve this, with DevOps as an integral system component, by leveraging real microservice architectures and agility.
In the past, development and operations teams had a significant contention. While developers used to burden all the code to the operations team, the operations team was expected to keep the code up and running in production. The developers focused on pacing up for rolling out new features faster, whereas the operations team focused on being slow and steady for system stability. This misalignment caused contention within organizations.
SRE – A Prescriptive Framework for Successfully Accomplishing DevOps
Site reliability engineering has gained a widespread prevalence as a concrete foundation for DevOps implementation. The difference between SRE and DevOps is that the former rides on the shoulders of developers who have also had a sound background in operations. Therefore, SRE implementation removes the workflow and communication problems more effectively.
Focusing on the overlap in responsibilities, the SRE model helps organizations amalgamate the skill set of their operations team and development team. Moreover, it provides support to the DevOps team, in the case when developers are saturated by tasks of operations and require more specialized knowledge. Based on new features and code bases, while DevOps emphasizes moving efficiently through development pipelines, SRE focuses on maintaining the right balance between creating new features and reliability.
SRE vs DevOps – Radical Differences
DevOps focuses on what is required to be done, whereas Site Reliability Engineering focuses on how things are required to be done. This is what makes them complement one another. However, there are some fundamental differences between the two.
| DevOps | Site Reliability Engineering |
|---|---|
| Reduce organization silos | Share ownership with developers by using the same tools and techniques across the stack |
| Accept failure as normal | Have a formula for balancing accidents and failure against new releases |
| Implement gradual change | Encourage moving quickly by reducing costs of failure |
| Leverage tooling & automation | Encourages “automating this year’s job away” and minimizing manual systems work to focus on efforts that bring long-term value to the system |
| Measure everything | Believes that operations is a software problem, and defines prescriptive ways for measuring availability, uptime, outrages, toil, etc. |
Gradual Change Implementation
The time-to-market has significantly reduced, with organizations and their customers expecting faster results. This has led to frequent releases and continuous improvements, thereby enabling teams to remain updated with emerging technologies and tools. This further empowers organizations in accelerating their software engineering cycle. While Devops ensures gradual changes to processes, SRE hinges on reducing failure cost as and when new releases are made.
Measurement
Irrespective of the approach followed, SRE or DevOps, measuring everything is imperative. While DevOps measures everything at operations and development phases, SRE emphasizes operations to be the achilles heel of most issues. Therefore, prescriptive measuring with aspects such as efforts, outages, uptime, and availability is emphasized in SRE.
Removing Silos within Organizations
Large organizations have their teams operating in distributed directions, which further creates silos and makes reliability challenging. While DevOps is focused on eliminating silos within organizations, SRE enables sharing ownership of production with developers. A single tool is used so that both operators and developers have the same approach of working abreast production.
Accepting Failure as Normal
DevOps concentrates on preventative measures for any issue, however, it accepts failure as inevitable, in turn making the teams learn and grow. On the other hand, SRE identifies the root cause of issues, trying to balance new releases against failures. Key identifiers of issues in SRE are classified into service-level objectives (SLOs) and service-level indicators (SLIs).
Automation and Tooling
Both SRE and DevOps focus on automation. Both of these approaches favor integration of new tools for supporting automation. This is as far as organizations realize measurable outcomes and benefits to operations and development teams by eliminating any manual effort or intervention.
To Conclude
Organizations need both DevOps and SRE in collaboration if they look to manage and avoid failures. Both approaches are meant for automating vital processes. While DevOps and site reliability engineering differ in various ways, they complement each other to bring high reliability to organizations. Organizations must analyze the data they have while measuring failure or success of implementing DevOps Vs SRE approaches in their business.
FAQs
| Is SRE better than DevOps? |
| SRE focus is on reliability and automation, while DevOps emphasizes collaboration and continuous delivery, making them both valuable approaches depending on the organizational needs and goals. |
| What is the role of DevOps and SRE? |
| The role of DevOps is to foster collaboration between development and operations teams, while SRE (Site Reliability Engineering) focuses on ensuring system reliability, scalability, and performance through automation and monitoring. |
| Similarities between SRE vs DevOps |
| Both SRE (Site Reliability Engineering) and DevOps emphasize collaboration, automation, and continuous improvement to enhance system reliability, scalability, and performance in modern IT environments. |
| Is SRE a subset of DevOps? |
| No, SRE is more like a partner to DevOps, focusing on reliability within the broader DevOps culture. |
Recommended Read:


