
























































The customer is a leading housing finance company, one of the most diversified NBFCs, which makes it one of the most profitable companies in the category. The main objective of the company is to provide long-term finance to individuals as well as corporate entities for purchase, construction, and renovation of homes, plots or commercial spaces. The customer approached Blazeclan for a seamless solution that reduces delays and manual overhead in their loan processes.
The Challenge
The customer used to face several challenges in terms of documentation, approvals on attestations of documentations, and delays in the resolutions of queries due to disputes in ownership. On account of these issues, the customer was looking for an analytical solution that addresses the aforementioned issues for the following documents.
- Loan Application Documents
- Transaction Documents
- Classification of query-related emails
It was highly crucial for the customer to carry out the assessing of all these documents and maintain a methodical database for effortless accessibility. Moreover, all of the documents were needed to be free of errors in terms of text, formatting, attestations, etc.
The Solution
The customer partnered with Blazeclan for building a robust and effective solution that helps them with easy access and availability of their documents in a methodical manner for eliminating process delays and manual overhead. Blazeclan proposed the customer with a solution that leverages Amazon Textract for identifying, understanding, and extracting information from their documents to make them error-free and represent them in graphical and tabular formats.
Amazon Textract was used as a tool for the conversion of images to textual files. These textual files were further stored in methodical databases for analysis and deriving insights to take preventive actions and make better decisions.
The Approach Followed
Loan Application Documents
These documents were required to be validated and approved by loan managers at the customer’s end. For this purpose, all information in these documents, including the applicant’s name, account number, application’s nature, proof of identification, were analyzed. Also, the documents of proof submitted by applicants, original, xerox, or certified, were also analyzed for errors and prevention of fake documents. These were then stored in Amazon RDS for effective, scalable storage and easy accessibility.
Transaction Documents
Details of the applicants, such as identification, insurance content, loan tenure, processing fee, insurance term in years, and the sum insured, were tracked and analyzed in the documents submitted by the customer to the applications. These details were also used while making the dashboard that facilitated identifying and accessing documents as and when required by the loan managers for validation, approval, and verification.
Classification of Query Related Emails
There were several disputes regarding the entitlement of query resolution between professionals at the customer’s end. However, Blazeclan’s solution, integrated with ML model for email, enabled a systematic classification of query emails that facilitated assigning of the query to the support team professionals based on the query’s nature and requirement. This further helped the customer to see faster resolution and reduced queues of queries. The classification involved nearly 200 to 250 groups of queries.
Blazeclan’s data mart team created a generic Textract processing pipeline, wherein the documents’ data was uploaded to get the output text data for table structures, headings, images, etc. This further offered the customer with a comprehensive database of critical information in the form of graphs. To achieve this, Amazon S3, Amazon SQS, and AWS Lambda were used along with Amazon Textract.
Architecture Diagram
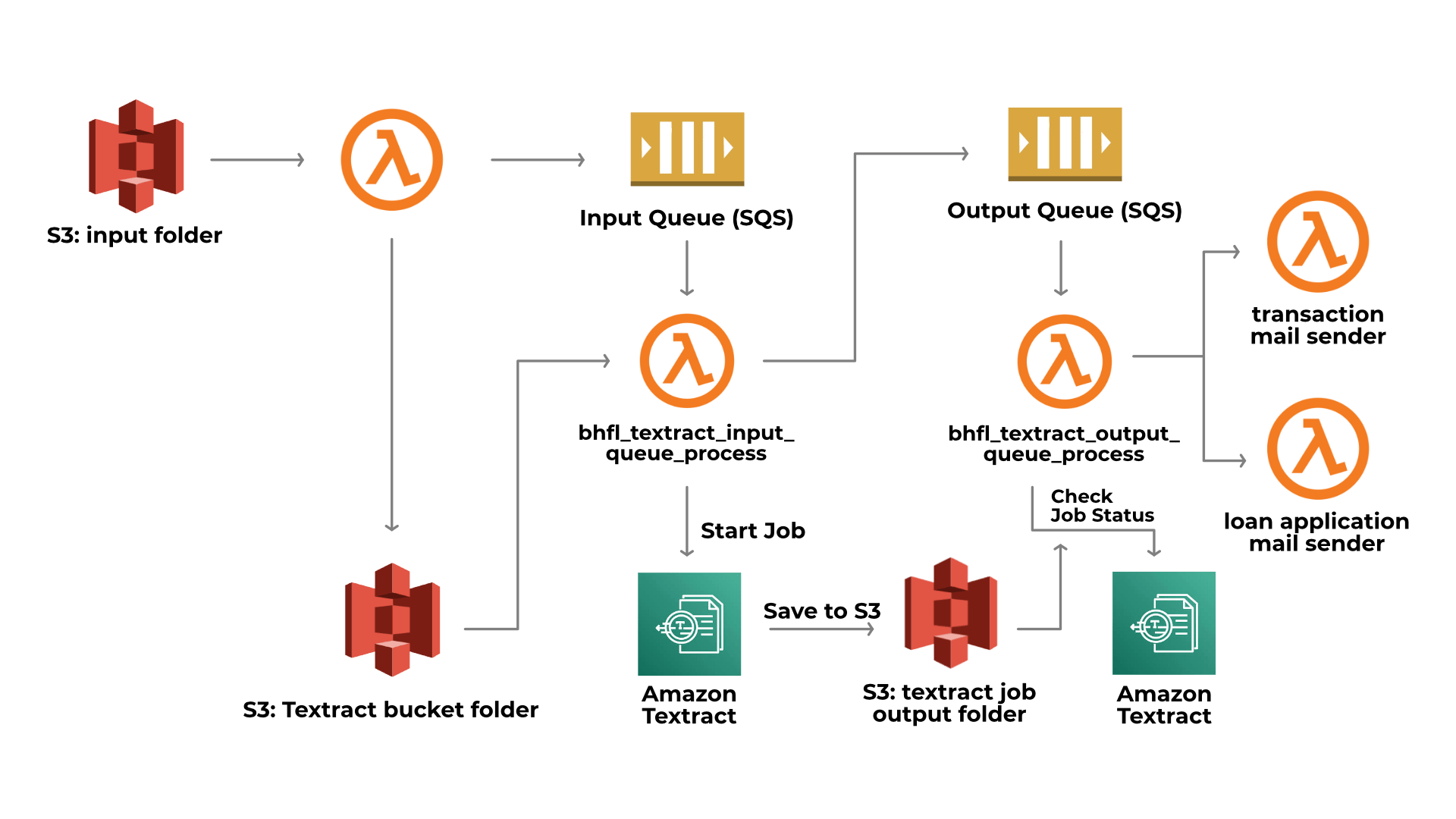
Benefits Achieved by The Customer
- The customer was delivered with a single pipeline for text extraction of all Documents – loan application, transaction, and query email classification. The documents were then analyzed based on their nature. This helped the customer reduce manual overhead significantly.
- Dashboard – Storing all crucial documents in a highly available database helped the customer to reduce errors and time needed to analyze, view, and access the data as per requirements.
- Text identification and extraction improved significantly with the implementation of Amazon Textract, which in turn spurred the verification process of all crucial documents.
- Email classification with the ML model increased the rate of query resolutions while considerably reducing human efforts and errors.

Tech Stack
| Amazon Textract | AWS Lambda | Amazon S3 |
| Amazon SQS | Amazon RDS | Amazon SageMaker |





